How do we have trust in a system that operates without oversight and inherent security?

Trust and bias in artificial intelligence (AI) are becoming increasingly important issues as AI systems are being deployed in a variety of settings, including criminal justice, healthcare, and hiring. At the same time, the public’s sentiment towards AI is complex, with some people expressing concern about the potential for AI to be biased or to be used in ways that are harmful to society, while others are more optimistic about the potential benefits of AI.
In this article, we will explore these issues in greater depth, examining the ways in which trust and bias can affect the deployment and use of AI, and looking at the regulatory frameworks that are being developed to address these concerns.
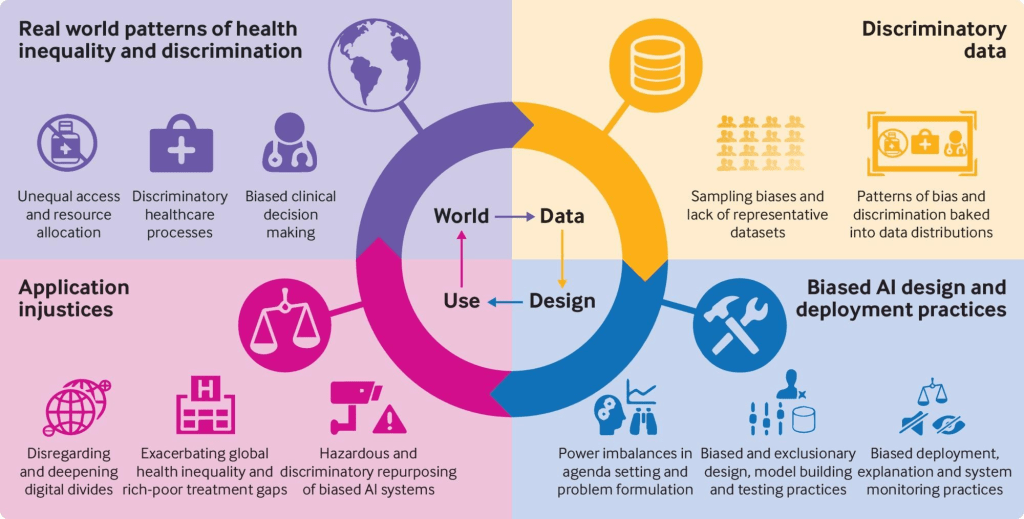
One of the key concerns about AI is the potential for it to be biased. This can occur in a number of ways, including through the data that is used to train the AI system, the algorithms that are used to analyze that data, and the decisions that are made based on the output of those algorithms. For example, if an AI system is trained on data that is biased in some way, it is likely to make biased decisions as well. This can have serious consequences, particularly if the AI system is being used to make decisions about things like criminal justice or hiring, where the stakes are high.
There is also a growing concern about the ways in which AI can be used to perpetuate existing biases or to amplify them. For example, if an AI system is used to screen job applicants, it may be more likely to recommend candidates who are similar to the people who have been successful in the past, leading to a lack of diversity in the hiring process. Similarly, if an AI system is used to predict the likelihood of a person committing a crime, it may be more likely to label people of certain races or socioeconomic backgrounds as “high risk,” leading to discrimination and unfair treatment.
What are the types of AI bias?
AI systems contain biases due to two reasons:
Cognitive biases: These are unconscious errors in thinking that affects individuals’ judgements and decisions. These biases arise from the brain’s attempt to simplify processing information about the world. More than 180 human biases have been defined and classified by psychologists. Cognitive biases could seep into machine learning algorithms via either:
- designers unknowingly introducing them to the model
- a training data set which includes those biases
Lack of complete data: If data is not complete, it may not be representative and therefore it may include bias. For example, most psychology research studies include results from undergraduate students which are a specific group and do not represent the whole population.
What is being done to address these issues?
To address these concerns, there is a growing movement to develop regulatory frameworks for AI.
These frameworks are designed to ensure that AI systems are transparent, accountable, and fair, and to protect the rights and interests of individuals who may be affected by the decisions made by these systems. Some of the key elements of these frameworks include requirements for companies to disclose the algorithms they are using, to allow individuals to access and challenge the data that is being used to make decisions about them, and to ensure that there are mechanisms in place to correct errors and prevent harm.
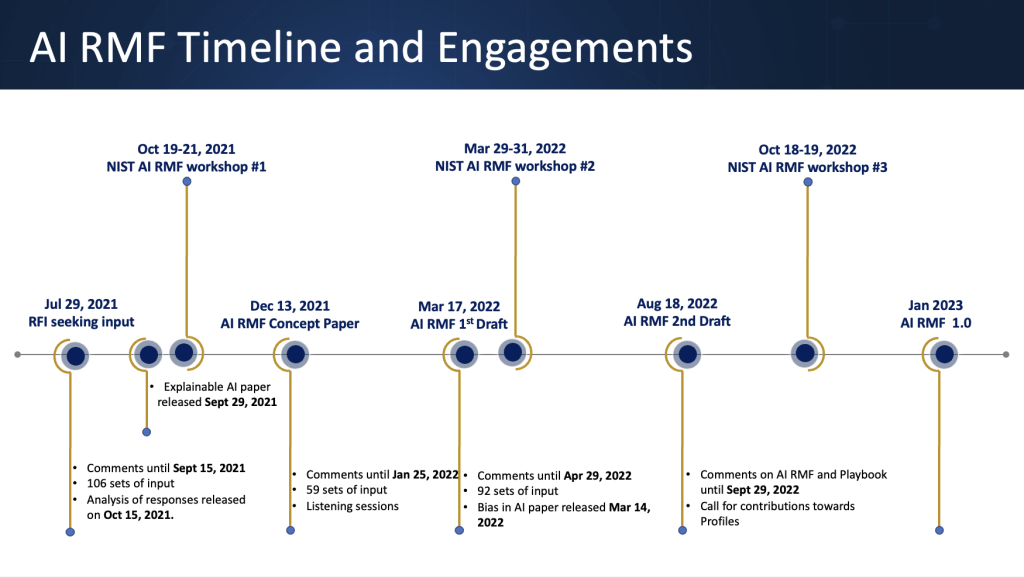
NIST (National Institute of Standards and Technology in the USA) is developing a framework to better manage risks to individuals, organizations, and society associated with artificial intelligence (AI). The NIST AI Risk Management Framework (AI RMF) is intended for voluntary use and to improve the ability to incorporate trustworthiness considerations into the design, development, use, and evaluation of AI products, services, and systems.
Despite these efforts, there is still a long way to go in terms of building trust in AI. Many people remain skeptical of the technology, and there are valid concerns about the potential for it to be used in ways that are harmful to society. However, by addressing the issues of bias and transparency, and by developing effective regulatory frameworks, it may be possible to build trust in AI and to ensure that it is used in ways that are beneficial to society.
Securing the integrity of AI Systems
From the second draft of the NIST AI RMF (Section 4.4. Secure and Resilient), here is what it says about security:
“AI systems that can withstand adversarial attacks, or more generally, unexpected changes in their environment or use, or to maintain their functions and structure in the face of internal and external change, and to degrade gracefully when this is necessary (Adapted from: ISO/IEC TS 5723:2022) may be said to be resilient. AI systems that can maintain confidentiality, integrity, and availability through protection mechanisms that prevent unauthorized access and use may be said to be secure. Security and resilience are related but distinct characteristics. While resilience is the ability to return to normal function after an attack, security includes resilience but also encompasses AI RMF 2nd Draft for public comment by September 29, 2022, 15 protocols to avoid or protect against attacks. Resilience has some relationship to robustness except that it goes beyond the provenance of the data to encompass unexpected or adversarial use of the model or data. Other common security concerns relate to data poisoning and the exfiltration of models, training data, or other intellectual property through AI system endpoints.”
AI systems are just as exposed as other technology platforms from an infrastructure perspective. However, attacks on the platform may be a bit more insidious than what you may seen in traditional infrastructure. The true value to an attacker is not from performing DoS attacks, or ransom, or any of the regular suspects, it is from data poisoning, and supply chain attacks. Here are some examples of those threats:
Data poisoning attack
There are two ways to poison data. One is to inject information into the system so it returns incorrect classifications.
At the surface level, it doesn’t look that difficult to poison the algorithm. After all, AI and ML only know what people teach them. Imagine you’re training an algorithm to identify a horse. You might show it hundreds of pictures of brown horses. At the same time, you teach it to recognize cows by feeding it hundreds of pictures of black-and-white cows. But when a brown cow slips into the data set, the machine will tag it as a horse. To the algorithm, a brown animal is a horse. A human would be able to recognize the difference, but the machine won’t unless the algorithm specifies that cows can also be brown.
If threat actors access the training data, they can then manipulate that information to teach AI and ML anything they want. They can make them see good software code as malicious code, and vice versa. Attackers can reconstruct human behavior data to launch social engineering attacks or to determine who to target with ransomware.
The second way threat actors could take advantage of the training data to generate a back door.
Hackers may use AI to help choose which is the most likely vulnerability worth exploiting. Thus, malware can be placed in enterprises where the malware itself decides upon the time of attack and which the best attack vector could be. These attacks, which are, by design, variable, make it harder and longer to detect.
An important thing to note with data poisoning is that the threat actor needs to have access to the data training program. So you may be dealing with an insider attack, a business rival or a nation-state attack.
Supply chain attacks
The building blocks of an AI system are comprised of multiple software components that rely on open source software. If any of those packages or modules, are compromised then this will impact the overall integrity of the platform. One way to do this is to compromise the source code of those packages. At the the end of December 2022, a commonly used component, called PyTorch was compromised. This affected thousands of people that pulled the nightly build from the repo. Although the attacker that has since claimed responsibility said that this was an exercise in highlighting the vulnerability, the attack did the following:
“Reports have claimed that the malicious dependency has already been downloaded more than 2,000 times already, and it grabs all sorts of sensitive data, from IP addresses and usernames, to current working directories. It also reads the contents of /etc/hosts, /etc/passwd, and The first 1,000 files in $HOME/*, among other things.”
Discover more from Designing Risk in IT Infrastructure
Subscribe to get the latest posts sent to your email.
