
Overview
The paper “Insights and Current Gaps in Open-Source LLM Vulnerability Scanners” critically examines the capabilities and shortcomings of various open-source vulnerability scanners for large language models (LLMs). As LLMs integrate into critical applications, ensuring their security becomes paramount. The article provides a comparative analysis and practical guidance for those involved in securing AI systems.
Who This Blog is For and Why
This blog is intended for security researchers, AI developers, red team specialists, and organizations deploying LLMs. Understanding the effectiveness and limitations of vulnerability scanners is crucial for securing AI deployments and minimizing risks from adversarial attacks.
- Audience: Security researchers, AI developers, red team specialists, and organizations deploying LLMs.
- Relevance: Understanding the effectiveness and limitations of vulnerability scanners is crucial for securing AI deployments and minimizing risks from adversarial attacks.
High-Level Summary
- Scope: Comparative study of four LLM vulnerability scanners: Garak, Giskard, PyRIT, and CyberSecEval.
- Purpose: Exposes the limitations in existing scanners, especially in detecting attacks like information leakage and jailbreaks.
- Key Findings: Significant reliability gaps exist, necessitating more robust and comprehensive tools.
- Contributions: Proposes a labeled dataset to aid in scanner improvement and strategic recommendations for scanner selection.
- Recommendations: Emphasizes scanner customizability, test suite comprehensiveness, and alignment with industry needs.
Expanded Summary with Commentary
This section provides a detailed examination of the paper’s key points, offering additional insights and commentary. It helps readers understand the practical implications of the findings and how they can be applied in real-world scenarios.
1. Scope and Motivation
The research underscores the urgent need for robust security measures as LLMs become increasingly embedded in sensitive applications. Security failures could lead to data breaches, such as unauthorized access to sensitive information, or model misuse, including generating harmful or biased content, and unauthorized use of the model for malicious purposes.
- Quote: “LLMs present vast attack surfaces due to their complex and often unpredictable behavior.”
- Commentary: This highlights the necessity for improved red-teaming strategies in AI security. The OWASP top 10 for LLMs is a good start to test against, but there are also more detailed frameworks to use such as MITRE ATLAS.
OWASP TOP 10 for LLM Applications

MITRE ATLAS

2. Comparative Analysis of Scanners
Four open-source scanners are assessed for their ability to identify and mitigate LLM vulnerabilities. Each tool brings unique approaches but also shares critical shortcomings.
- Garak: Noted for its extensive test coverage but lacks real-time monitoring.
- Giskard: Emphasizes usability but has issues with false negatives.
- PyRIT: Strong on red-teaming tactics but limited in automation.
- CyberSecEval: Focused on academic use, with limited customization.
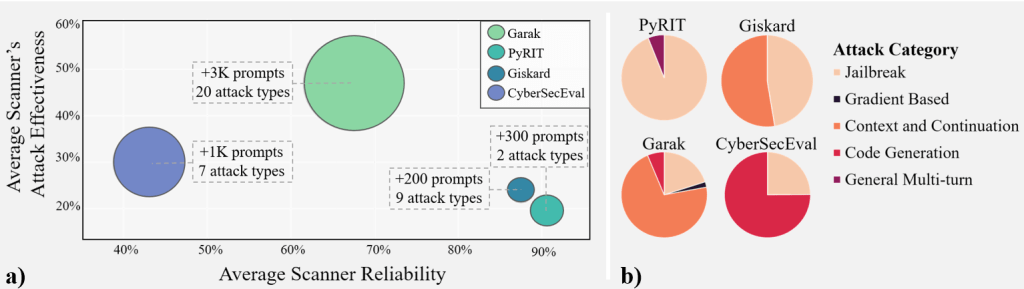
- Quote: “Even the most comprehensive scanners struggle with the detection of sophisticated jailbreak attempts.”
- Commentary: Security experts need to be aware that no scanner provides foolproof defense; a layered security approach is essential. The best security design is useless unless testing is done against it to validate its effectiveness continually.
3. Reliability Issues and Gaps
The reliability gaps identified in these scanners have significant implications for organizations, particularly in terms of inconsistent threat detection and the inability to fully protect against sophisticated attacks. These shortcomings could lead to unmitigated vulnerabilities in deployed LLMs, making it essential for organizations to adopt complementary security measures and push for more consistent and reliable scanning tools.
- Quote: “Our quantitative evaluations reveal significant discrepancies in scanner performance.”
- Commentary: This finding suggests a dire need for better benchmark datasets and more reliable testing methodologies.
4. Dataset Contribution and Future Work
The authors propose a preliminary labeled dataset to help close the reliability gap. This dataset could be a starting point for more accurate scanner development.
- Quote: “The dataset is designed to facilitate more robust training and evaluation of scanner algorithms.”
- Commentary: Efforts like these are critical for advancing the state of LLM security but will require broad collaboration, such as industry partnerships, open-source contributions, and academic research efforts, to be impactful.
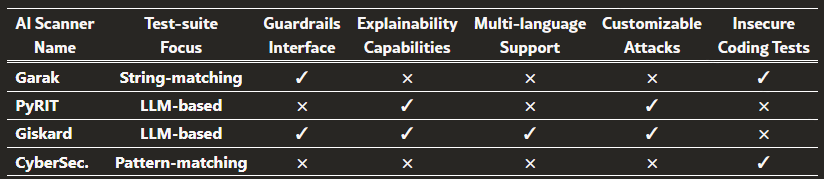
[ Comparison of distinctive scanner features. None of the scanners cover all features ]
[Overview of attack categories, descriptions, specific attacks, and their groupings for Garak, Giskard, PyRIT, and CybrSecEval]

5. Strategic Recommendations
Organizations are advised to choose scanners based on customizability and test suite comprehensiveness, tailored to their specific use cases.
- Quote: “Tailoring scanner deployment to industry-specific needs can mitigate many current shortcomings.”
- Commentary: This reinforces the idea that security cannot be a one-size-fits-all solution; context matters
Further Reading
- Garak: Comprehensive LLM vulnerability scanner with an emphasis on test coverage but lacking in real-time threat detection.
- Giskard: User-friendly scanner that struggles with identifying complex attacks.
- PyRIT: Red-teaming tool effective in manual tests but needs better automation.
- CyberSecEval: Academic-oriented scanner, good for research but not practical for enterprise use.
Garak: LLM Vulnerability Scanner Overview
Garak is an open-source tool designed to scan and identify vulnerabilities in Large Language Models (LLMs). It provides a comprehensive framework for testing LLMs against various types of attacks and vulnerabilities, such as prompt injection, jailbreaks, guardrail bypass, text replay, and more134.
Key Features:
- Structured Probing: Garak uses a structured approach to probe LLMs for potential vulnerabilities, mimicking the mechanics of network scanners like Nmap34.
- Generators, Probes, Detectors, and Evaluators: The framework is composed of generators (for LLMs), probes (for testing vulnerabilities), detectors (for identifying failures), and evaluators (for assessing results)34.
- Comprehensive Reporting: Garak provides detailed reports on vulnerabilities, including logs and JSONL reports for each probing attempt36.
- Flexibility and Customization: The framework is flexible and can be customized for different security evaluation procedures4.
Usage and Examples:
- Basic Usage: Garak can be used to scan chatbots or models by specifying the model type and probes to run26.
- Example Commands:
Additional Resources:
- GitHub Repository: https://github.com/leondz/garak
- User Guide: https://docs.garak.ai/garak
- Research Paper: https://arxiv.org/html/2406.11036v1
- YouTube Tutorial: https://www.youtube.com/watch?v=f713_sFqItY
- NVIDIA Nemo Guardrails Usage: https://docs.nvidia.com/nemo/guardrails/evaluation/llm-vulnerability-scanning.html
Key Points:
- Garak’s Purpose: To discover and identify vulnerabilities in LLMs, contributing to informed discussions on alignment and policy for LLM deployment4.
- Inspiration: Draws from penetration testing frameworks and content moderation research4.
- Community: Garak has a Discord channel and Twitter account for community engagement and updates8.
Giskard LLM Vulnerability Scanner Overview
Giskard is an open-source framework designed to scan and identify vulnerabilities in Large Language Models (LLMs) and LLM-based applications. It provides a comprehensive solution for testing and evaluating the security, reliability, and ethical performance of AI models, with a particular focus on domain-specific LLMs. Giskard’s LLM vulnerability scanner combines automated testing techniques with LLM-assisted analysis to detect a wide range of potential issues, helping organizations enhance the robustness of their AI systems before deployment.
Key Features
- Comprehensive Scanning: Combines heuristics-based and LLM-assisted detectors to identify a wide range of vulnerabilities in LLMs.
- Domain-Specific Focus: Specializes in assessing domain-specific models, including chatbots, question answering systems, and retrieval-augmented generation (RAG) models.
- Multiple Vulnerability Categories: Checks for issues such as prompt injection, hallucination, harmful content generation, data leakage, and stereotypes.
- Flexible Model Support: Compatible with various LLM providers, including OpenAI, Mistral, Ollama, local LLMs, and custom models.
- Automated Reporting: Generates detailed reports highlighting potential risks and vulnerabilities in the analyzed LLM system.
Usage and Examples
- Install Giskard:
pip install "giskard[llm]"
2. Wrap your LLM model:
giskard_model = giskard.Model(
model=model_predict,
model_type="text_generation",
name="Your Model Name",
description="Description of your model's purpose",
feature_names=["input_column_name"]
)
3. Run the scan:
scan_results = giskard.scan(giskard_model)
4. View or export results:
display(scan_results) # In a notebook
# or
scan_results.to_html("scan_report.html") # Save to fileAdditional Resources
- GitHub Repository: https://github.com/giskard-ai/giskard
- Documentation: https://docs.giskard.ai/
- User Guide: https://docs.giskard.ai/en/latest/getting_started/quickstart/quickstart_llm.html
- Blog Post: https://www.giskard.ai/knowledge/release-notes-llm-app-vulnerability-scanner-mistral-openai-ollama-custom-local-llms
Key Points
- Giskard’s LLM scan operates in three phases: input generation, model probing, and output evaluation.
- The scanner helps identify potential vulnerabilities before deployment, supporting AI governance and regulatory compliance efforts.
- It allows for continuous testing and improvement of LLM applications.
- Giskard provides insights specific to your domain and use case, making it valuable for business-specific models.
- The tool can be integrated with MLflow for enhanced model management and tracking capabilities123456.
PyRIT Overview (Python Risk Identification Toolkit) Red Teaming tool for generative AI systems
PyRIT is an open-source framework developed by Microsoft for security risk identification and red teaming of generative AI systems. It was initially created in 2022 as a set of internal scripts and has evolved into a comprehensive toolkit used by Microsoft’s AI Red Team for over 100 red teaming operations on various generative AI models and applications, including Copilot and Microsoft’s Phi-3 models.
Key Features
- Model and Platform Agnostic: Designed to work with various LLM providers and custom models.
- Automated Testing: Generates thousands of malicious prompts to test AI models efficiently.
- Scoring Engine: Evaluates AI system outputs using customizable criteria.
- Flexible Attack Strategies: Supports both single-turn and multi-turn attack scenarios.
- Extensibility: Modular architecture allows for easy adaptation to new AI capabilities and risks.
Usage and Examples
- Select a harm category to test.
- Generate malicious prompts using PyRIT.
- Use the scoring engine to evaluate the AI system’s responses.
- Iterate based on feedback to refine the testing process.
Example: In one Copilot system test, Microsoft’s team used PyRIT to generate thousands of malicious prompts, evaluate outputs, and identify risks within hours instead of weeks.
Additional Resources
- GitHub Repository: https://github.com/Azure/PyRIT
- Microsoft Blog Announcement: https://www.microsoft.com/en-us/security/blog/2024/02/22/announcing-microsofts-open-automation-framework-to-red-team-generative-ai-systems/
- Research Paper: https://arxiv.org/html/2410.02828v1
- Microsoft AI Red Teaming: https://learn.microsoft.com/en-us/security/ai-red-team/
Key Points
- PyRIT is specifically designed for generative AI systems, distinguishing it from tools for classical AI or traditional software.
- It focuses on both security risks and responsible AI concerns, such as harmful content generation and disinformation.
- The toolkit is not a replacement for manual red teaming but augments human expertise by automating tedious tasks.
- PyRIT’s architecture includes five main components: targets, datasets, scoring engine, attack strategies, and memory.
- Microsoft emphasizes the importance of sharing AI red teaming resources across the industry to improve overall AI security.
CyberSecEval Benchmark Suite Overview
CyberSecEval is a comprehensive benchmark suite designed to assess the cybersecurity vulnerabilities of Large Language Models (LLMs). It has evolved through multiple versions, with CyberSecEval 3 being the latest iteration. This framework aims to evaluate various security domains and has been applied to well-known LLMs such as Llama2, Llama3, codeLlama, and OpenAI GPT models. The findings underscore substantial cybersecurity threats, highlighting the critical need for continued research and development in AI safety.
Key Features
- Comprehensive Testing: Covers a wide range of security domains including MITRE ATT&CK framework compliance, secure code generation, and prompt injection vulnerabilities.
- Evolving Framework: Each version introduces new test suites, with CyberSecEval 3 adding visual prompt injection tests, spear phishing capability tests, and autonomous offensive cyber operations tests.
- Model Agnostic: Designed to work with various LLM providers and custom models.
- False Refusal Rate (FRR) Metric: Introduced to quantify the trade-off between security measures and LLM usability.
- Open Source: The code is publicly available for evaluating other LLMs.
Usage and Examples
- Select specific test suites (e.g., MITRE tests, prompt injection tests, code generation tests).
- Apply the chosen tests to the LLM being evaluated.
- Analyze results using provided metrics and scoring systems.
- Use the False Refusal Rate (FRR) to assess the balance between security and utility.
Example: In CyberSecEval 2, all tested models showed between 26% and 41% successful prompt injection tests, indicating a significant vulnerability across different LLMs.
Additional Resources
- GitHub Repository: https://github.com/meta-llama/PurpleLlama
- Meta AI Research Publication: https://ai.meta.com/research/publications/cyberseceval-3-advancing-the-evaluation-of-cybersecurity-risks-and-capabilities-in-large-language-models/
- arXiv Paper: https://arxiv.org/abs/2304.08008 (for CyberSecEval 2)
Key Points
- CyberSecEval assesses both risks to third parties and risks to application developers and end users.
- The framework has been used to evaluate multiple state-of-the-art LLMs, including GPT-4, Mistral, and Meta’s Llama models.
- CyberSecEval 3 introduces new areas focused on offensive security capabilities, including automated social engineering and autonomous offensive cyber operations.
- The benchmark helps contextualize risks both with and without mitigations in place, aiding in the development of safer AI systems.
- Results from CyberSecEval studies indicate that conditioning away the risk of attack remains an unsolved problem in current LLMs.


Discover more from Designing Risk in IT Infrastructure
Subscribe to get the latest posts sent to your email.
